AI News
How to Precisely Predict Your AI Model’s Performance Before Training Begins? This AI Paper from China Proposes Data Mixing Laws
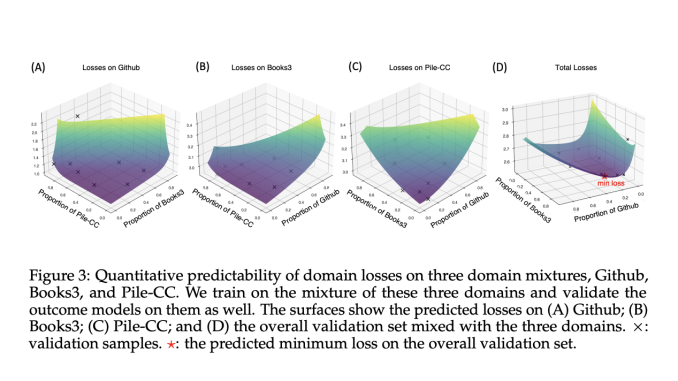
In large language models (LLMs), the landscape of pretraining data is a rich blend of diverse sources. It spans from common English to less common languages, including casual conversations and scholarly texts, and even extends […]